Introduction to HTTP
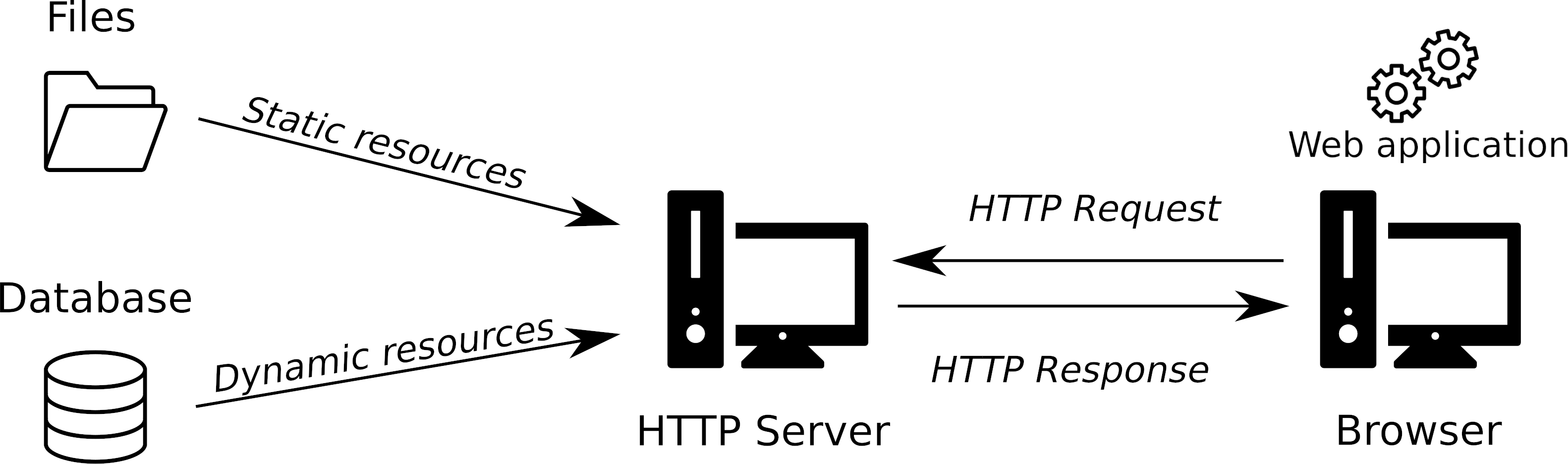
The Hypertext Transfer Protocol or HTTP enables communications between clients and servers and serves as a request-response protocol between the two.
For example, imagine a user interacting with the internet via a web browser. If that user wanted to request a resource from example.com, they'd type the URL (Uniform Resource Locator) in the location bar then the browser would send an HTTP/HTTPS request to the target server. In response, the server would send a response object containing a response body (data), which the browser parses and displays to the user.
Introduction to HTTPS
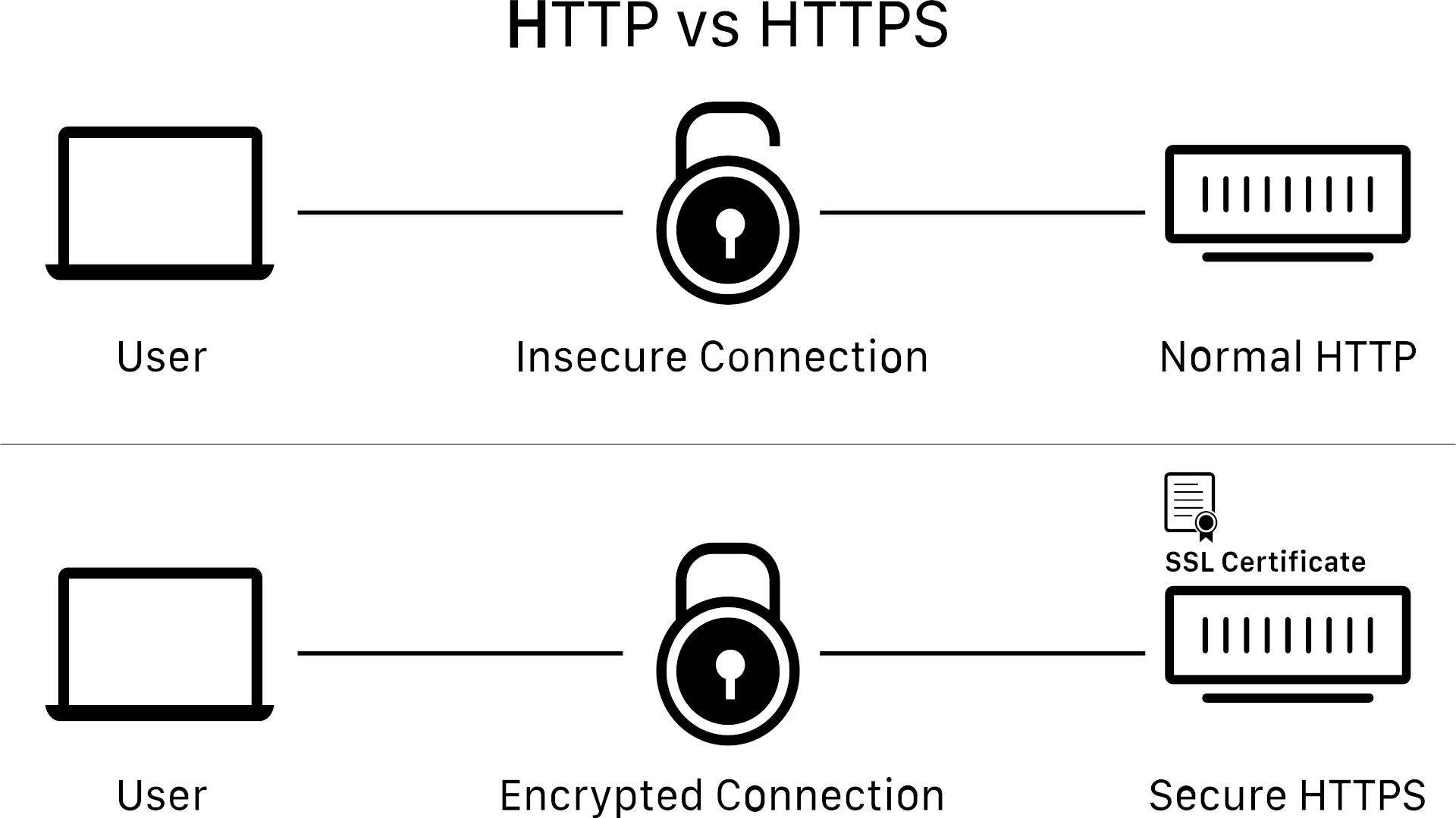
HTTPS stands for Hypertext Transfer Protocol Secure. In other words, it's HTTP with encryption. The only functional difference is that HTTPS encrypts request and response bodies using TLS/SSL, making HTTPS communications far more secure than unencrypted HTTP.
The only difference visible to the client is the URL. URLs for websites using the HTTP protocol start with http://, while those using HTTPS start with https://.
Note: In this tutorial, it's assumed that you're using HTTPS. If you're not, I strongly suggest you do.
HTTP headers
HTTP headers are used to provide information about HTTP requests and responses. All requests and responses have headers that provide details about the information of that request or response.
Then there are representation and payload headers, these can include information about the body (content) of the resource being transferred (E.G. MIME type, encoding and content length). Other uses for headers include authentication, instructions for caching data, or client device information.
Note: Required HTTP headers that aren't explicitly set by the client making the request are usually set to default by the server.
CRUD explained
Before we continue to what HTTP methods are, it helps to understand CRUD. CRUD stands for: Create, Read, Update and Delete, the four primary functions of persistent storage and can refer to operations performed by a database or a program that works with file systems.
Request methods
A request method is a type of request made to a server, and both HTTP and HTTPS support the same set of request methods.
Request methods can connect to servers and request information and resources from them. They can also send, create, modify or delete resources and debug a server response.
HTTP(S) GET
The HTTP GET method requests a specified resource. In response to this request, the server returns a body (of data) if nothing goes wrong.
While this type of request can include data, it shouldn't because some servers might refuse the request as there are other methods better suited to transferring data.
While not prohibited by the specification, the semantics are undefined. It is better to avoid sending payloads in GET requests.
HTTP(S) POST
The HTTP POST method is used to send data to the server and is better suited to sending data than the GET method. Its primary use is to request that the server accept the data enclosed in the request.
When you sign up for a website, make an online purchase or post a comment, the website you're on makes an HTTP POST request to the server that handles that data. That POST request contains all of the information you entered into the form.
HTTP(S) PUT
Both POST and PUT requests send data to the server. The difference is how the server handles the request. PUT requests update specific resources. If the resource already exists, an update operation occurs. If it doesn't, the server creates it (if the URI is valid).
Another difference is that PUT is idempotent. Making a PUT request once or several times successively has the same effect. In other words, if a particular update has already happened, it doesn't need to happen again. On the other hand, submitting identical POST requests multiple times will cause the server to handle the same data multiple times (for example, making multiple purchases).
Note: In this context, idempotent means that any number of repeated, identical requests will leave the resource in the same state.
HTTP(S) DELETE
As the name implies, the HTTP DELETE request method requests that the server delete the specified resource.
Note: The server doesn't always permanently delete the resource and might opt to perform a soft delete instead.
HTTP(S) PATCH
The HTTP PATCH method applies partial modifications to a resource. Unlike the PUT method, the PATCH method contains instructions describing how to deal with partial changes to a resource instead of modifying the entire resource.
HTTP(S) HEAD
Remember how the HTTP GET method requests a resource from a server? Well, the HTTP HEAD method requests the header data for that resource without actually sending any data.
An example of a use case for HTTP HEAD requests is in scenarios where the resource information is needed, but the resource isn't required immediately.
For example, a website that plays a music album. Instead of downloading all the songs on the album's page at once, the developer could opt to send HEAD requests (where no content is received) to show the information of each song (file size, file name, media type, etc...) and only send a GET request to load each music file after the user clicks the play button.
HTTP(S) OPTIONS
The HTTP OPTIONS method requests permitted communication options for a URL or server. A good use for HTTP OPTIONS would be to find out the supported HTTP methods of the target resource before sending an actual HTTP request.
HTTP(S) CONNECT
The CONNECT method starts two-way communications with the requested resource and is used to open a tunnel.
Tunnelling, also known as "port forwarding," is the transmission of data intended for use only within a private network through a public network while ensuring that the routing nodes in the public network are unaware that the exchange is part of a private network.
During transmission, the private network's data is encapsulated in the public network's transmission units, causing the private network's protocol information to appear to the public network as data, allowing developers to use the Internet (a public network) as a tool to transmit data on behalf of private networks.
Note: A packet is a small segment of a set of data. Computer networks such as the internet divide and send data as smaller packets. The receiving computer then recombines them into the original data.
Note: In large networks, when a source node (a computer) sends packets, they are received and forwarded along a route until they reach the destination computer. This enables large networks to take the shortest path between the source node (a computer) and the destination node (another computer).
HTTP(S) TRACE
The HTTP TRACE method performs a message loop-back test between the client and the server (useful for debugging operations).
A loop-back test sends data from a source to a destination without making any modifications, letting the developer know if all the nodes in a network are working. Simply put, it helps trace changes in data that shouldn't have occurred to the node where the change occurred.
Safe and unsafe methods
A safe HTTP method is one that doesn't alter the server's state (one that performs read-only operations).
All safe methods are also idempotent, but not all idempotent methods are safe.
Safe HTTP(S) methods include:
- GET
- HEAD
- OPTIONS
- TRACE
The unsafe HTTP(S) methods are:
- POST
- PUT
- DELETE
- PATCH
- CONNECT
Closing thoughts
I wrote this article as a foundation for a web scraping project I'm currently working on. It is not a mandatory read to understand that project, but, as stated in the title, it is a non-technical introduction to this topic, and I've kept it code-free to help readers understand what's happening behind the scenes. You can read about the implementation of these methods in the upcoming follow-up article.
Thank you for reading.